AMD今日正式发布CDNA 4架构及Instinct MI350系列GPU,新架构在计算密度、能效比和内存带宽方面相比上代产品有显著的优化,同时支持灵活的硬件分区和开放 的生态系统,为生成式AI和大语言模型训练与推理带来突破性的性能提升。
AMD表示,CDNA 4架构的优点可以总结为4个部分,首先是针对生成式AI (GenAI) 和大型语言模型 (LLM) 配置的增强型矩阵引擎,同时为实现混合精度运算带来了新数据格式的支持,增强的Infinity Fabric总线以及先进的封装互连技术则为性能提升打下坚实的基础,在这三点基础上还实现了能效的进一步提升。

基于CDNA 4架构打造的Instinct MI350系列GPU就是这四个优点的最佳体现,其基于迭代升级后的芯片堆叠封装工艺打造,采用N3P工艺的加速器复合核心(XCD)通过COWOS-S封装技术堆叠在采用N6工艺的I/O核心(IOD) 之上,3D混合架构为带来了高性能密度和高能效比,IOD-IOD互连以及HBM3E显存的集成则基于2.5D架构打造。

AMD Instinct MI350系列GPU包含有8个XCD模块,每个XCD模块32组计算单元,共计256组,1024个矩阵核心,每个XCD配置2MB L2缓存;IOD基于2个N6工艺核心构成,提供有128通道HBM3E显存接口与256MB容量的AMD Infinity缓存;2个HBM3E显存采用8堆栈结构,每个堆栈为12层堆叠的36GB,数据频率为8Gbps,可提供8TB/s的显存带宽;内部所用的Infinity Fabric AP互联带宽达到5.5TB/s,外部连接则基于1075GB/s带宽的第四代Infinity Fabric总线与128GB/s带宽的PCI-E 5.0接口。
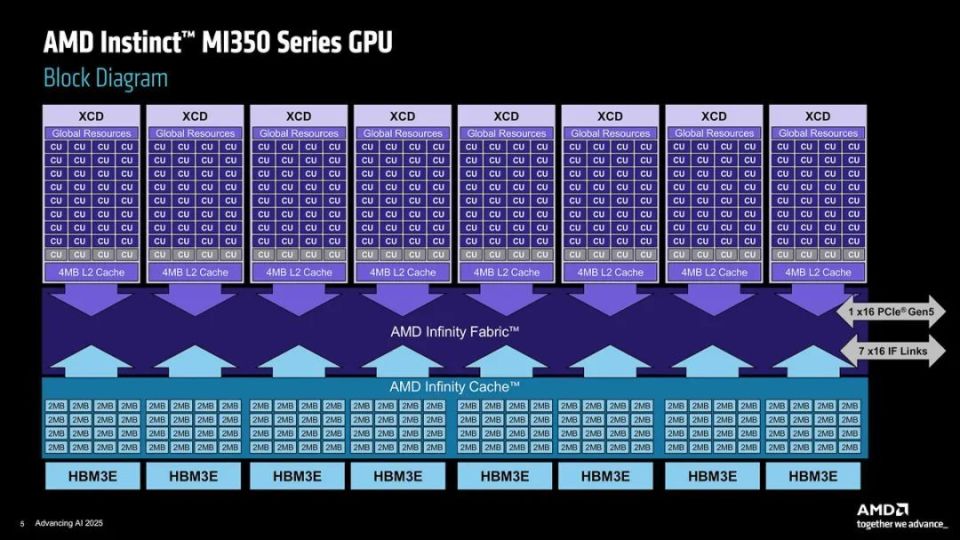
Instinct MI350系列GPU架构示意图

Instinct MI350系列可以支持多达8个空间分区,以实现GPU利用率的最大化,在SPX+NPS1模式下可以运行最高520B规模的AI模型,在CPX+NPS2模式下则支持8组Llama 3.1 70B模型实例。

8堆栈的HBM3E显存为Instinct MI350系列GPU带来了288GB的高容量与8TB/s的高读取带宽,可以在对显存带宽敏感的应用中,带来明显的使用体验提升。与上一代的Instinct MI300系列GPU相比,Instinct MI350系列GPU在每瓦HBM显存读取带宽性能上,最高可达前者的1.3倍。

每CU的HBM读取带宽是前代产品的1.5倍
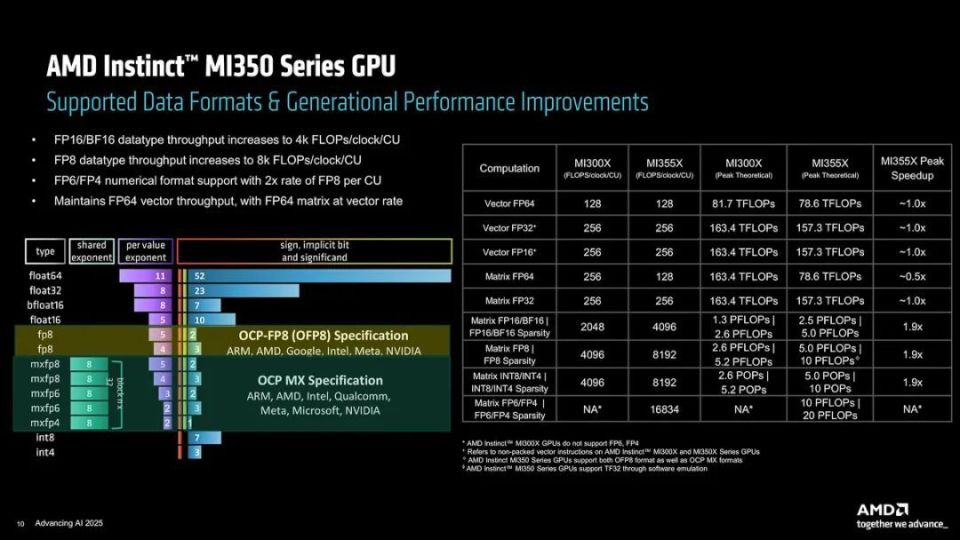
Instinct MI350系列GPU在数据格式支持与性能上相比前代产品有稳步提升,首先是实现了FP6与FP4的支持,这是Instinct MI300系列GPU无法实现的,FP6与FP4的每CU运算速率是FP8的2倍;在FP16/BF16/FP8/FP8/INT8/INT4的运行速度上相比上代产品也是有明显的提升,其中FP16/BF16数据吞吐量达到4K FLOPS/每时钟/每CU,FP8数据吞吐量则达到8K FLOPs/每时钟/每CU,可以达到相当于前代产品1.9倍的理论运算峰值。
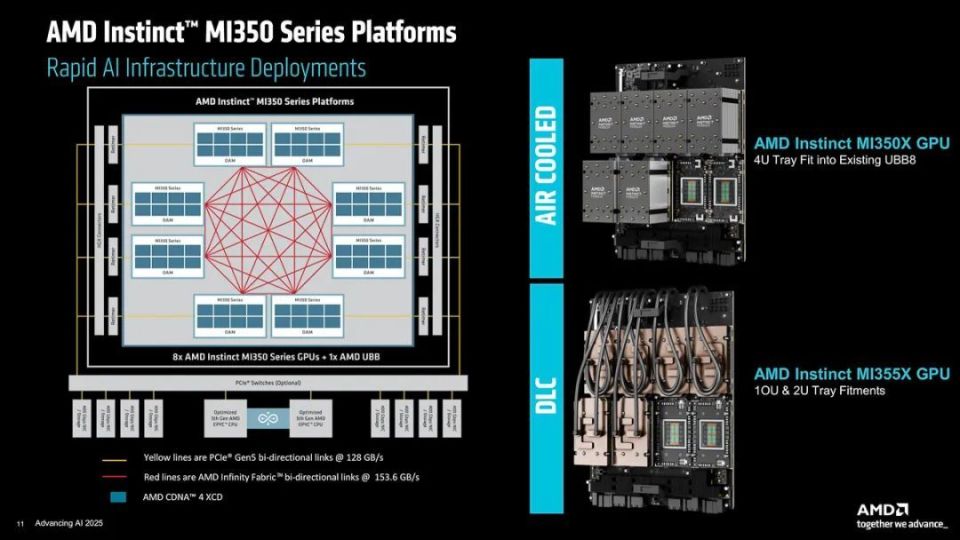
基于8个GPU模块组成的Instinct MI350系列平台的架构示意图

专为AI运算的GPU大都是以机架阵列的形式登场,Instinct MI350系列自然不会例外。采用第五代EPYC系列处理器、Instinct MI350系列GPU以及AMD Pollara NIC网卡的机架式阵列系统完全基于开放式标准打造,提供有DLC液冷方案与AC风冷方案可选,可满足不同使用需求的客户。

基于DLC液冷的MI355X方案整合有128个Instinct MI355X GPU,拥有36TB HBM3E显存,可提供644FP FP16/BF16、1.28EF FP8、2.57EF FP6/FP4运算性能;基于AC风冷的MI350X方案整合有64个Instinct MI355X GPU,拥有18TB HBM3E显存,可提供295FP FP16/BF16、590PF FP8、1.18EF FP6/FP4运算性能。

AMD不仅仅为AI运算带来了硬件上的性能提升,实际上他们一直致力于为开发者和用户带来全方位的生态系统,这就是AMD ROCm平台所需要实现的目标。在Instinct MI350系列GPU发布的同时,AMD也带来了ROCm 7平台,进一步深化生态系统的协作。

AMD ROCm 7平台不仅加入MI350系列GPU支持,同时对最新的AI算法与模型的使用也进行了深度的适配,为规模化AI带来了更多的先进功能,进一步提升了集群管理能力以及企业应用的兼容性。

ROCm 7带来的AI推理能力增强
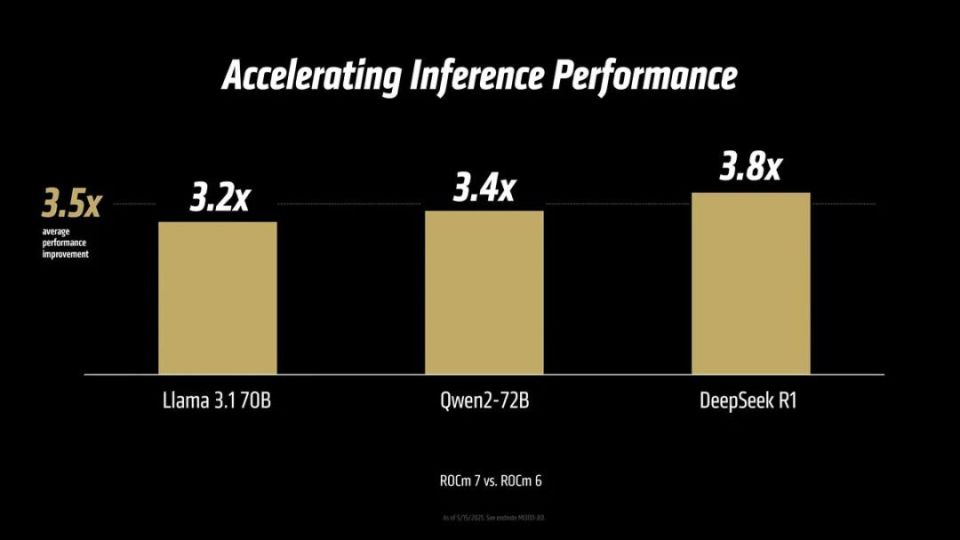
ROCm 7可以在推理性能带来明显的提升,与ROCm 6平台相比在Llama 3.1 70B上是后者3.2倍,Qwen2-72B为3.4倍,为3.8倍,统计下为平均3.5倍,可以说性能提升是非常显著的。
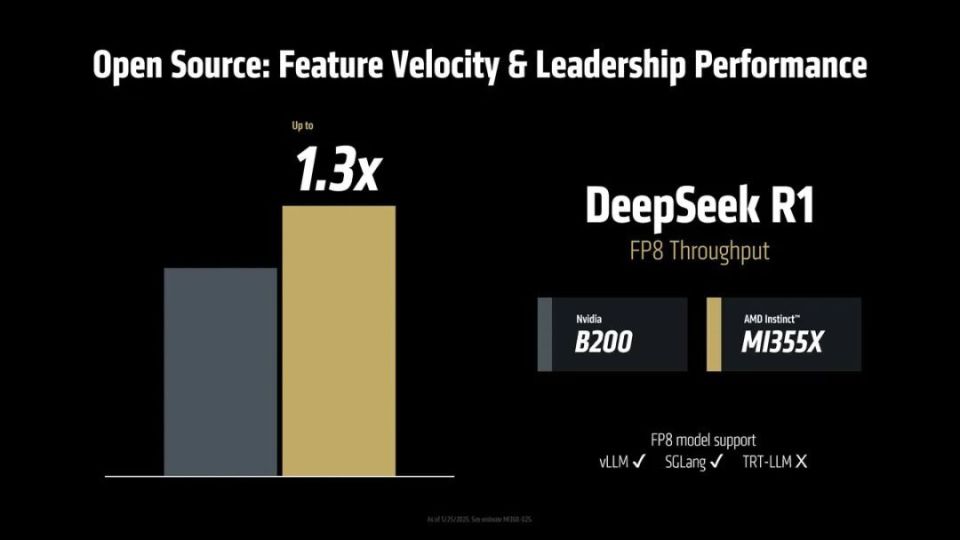
与对手的B200相比,MI355X在DeepSeek R1的FP8吞吐量可以达到1.3倍
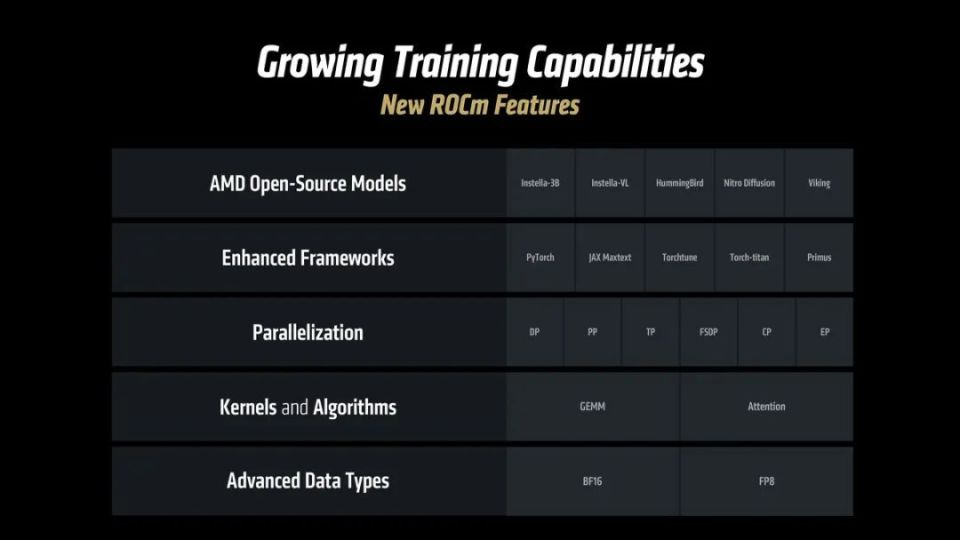
ROCm 7带来的训练能力增强
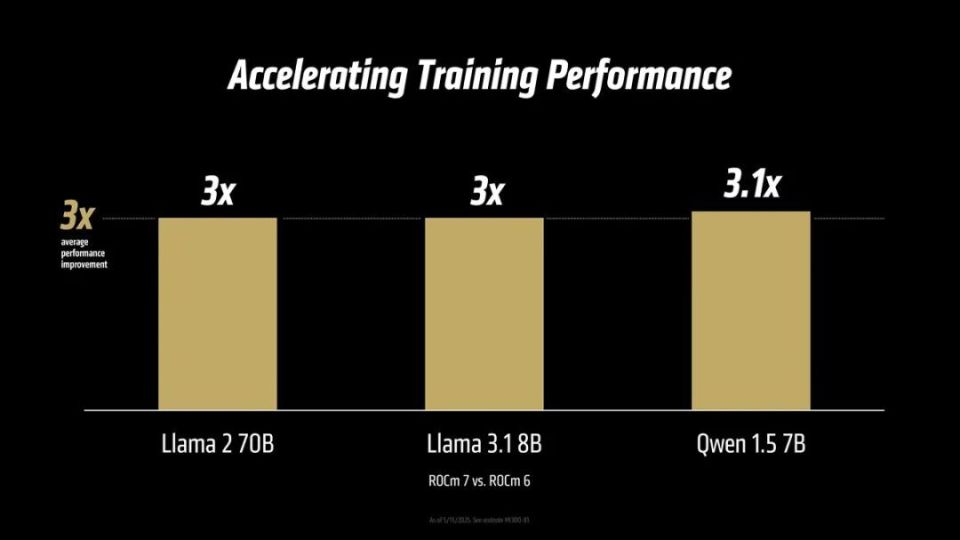
在训练能力方面,ROCm 7相比于ROCm 6也是有显著的提升,Llama 2 70B上是后者3倍,Llama 3.1 8B为3倍,Qwen 1.5 7B为3.1倍,统计下为平均3倍,可以说是全方位领先于ROCm 6平台。
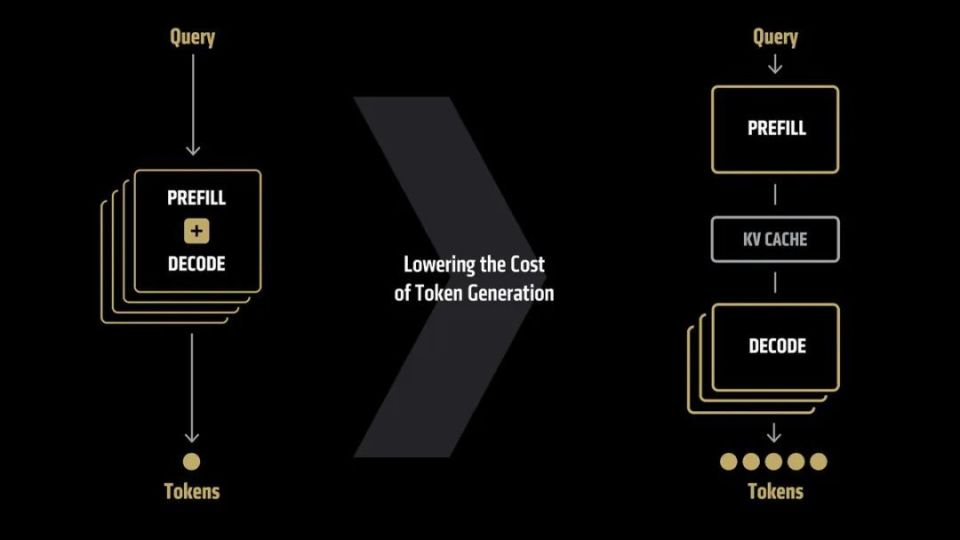
ROCm 7还降低了生成Token的成本

ROCm 7可以利用开放式系统实现规模化的分布式推理

ROCm 7可以称之为“企业Ready”型平台,因为其在端到端解决方案、安全数据集成以及便于部署等三个方面都进行了充分的优化。
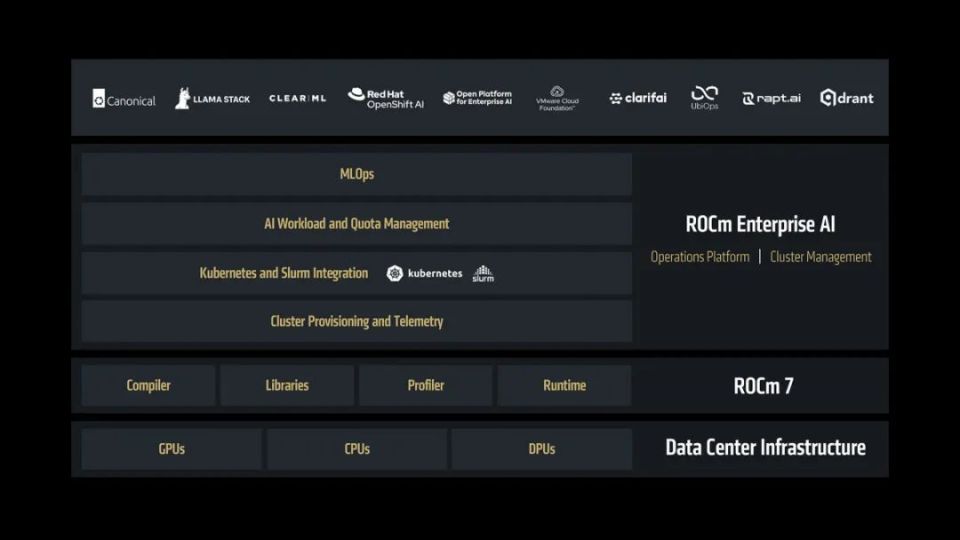
ROCm 7平台在企业AI应用中的作用示意图

AMD ROCm 7平台还有一个重要的特性,那就是其实现了完整的Windows平台支持

AMD致力于为所有需要AI系统的用户提供合适的解决方案
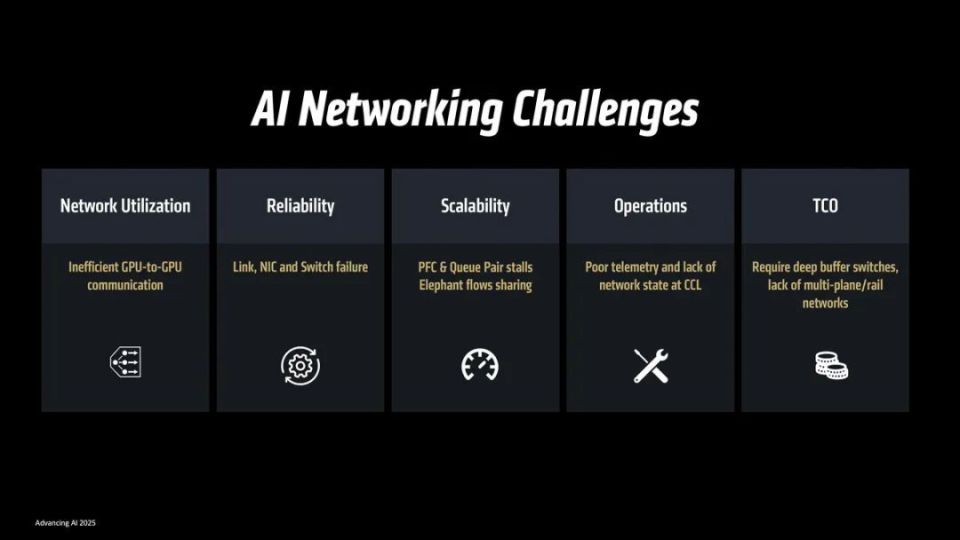
制约AI能力的不仅仅系统阵列本身的性能,对于规模化的AI阵列而言,阵列之间的互联速率往往会深度影响AI的推理与学习能力,总结下来可以说是有5大制约因素,分别是GPU到GPU的通讯能力,阵列互联网络的稳定性、阵列规模化难度、运维难度以及整体组建成本。

为了可以更好地减少这些制约因素的影响,AMD推出了业内首款基于超以太网络协议打造的AI NIC网卡Pensando Pollara 400,其具有完全可编程的传输层,可灵活支持各种网络协议,同时可以有效降低CPU负载,PCI-E 5.0接口实现了高速率的系统连接,无需专用网络结构即可轻松扩展。

Pensando Pollara AI NIC架构示意图
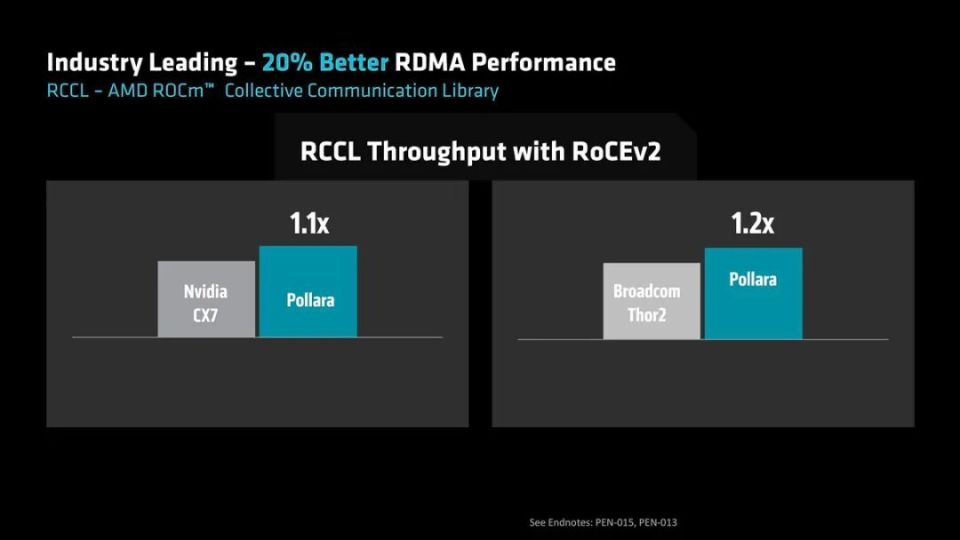
在RCCL(ROCm集合通讯库)吞吐量上,Pollara 400 AI NIC的速率是NVIDIA CX7的1.1倍,是博通Thor2的1.2倍,领先于直接的竞争对手。

Pollara 400 AI NIC网卡是UEC Ready产品,其基准性能方面是RoCEv2产品的1.25倍
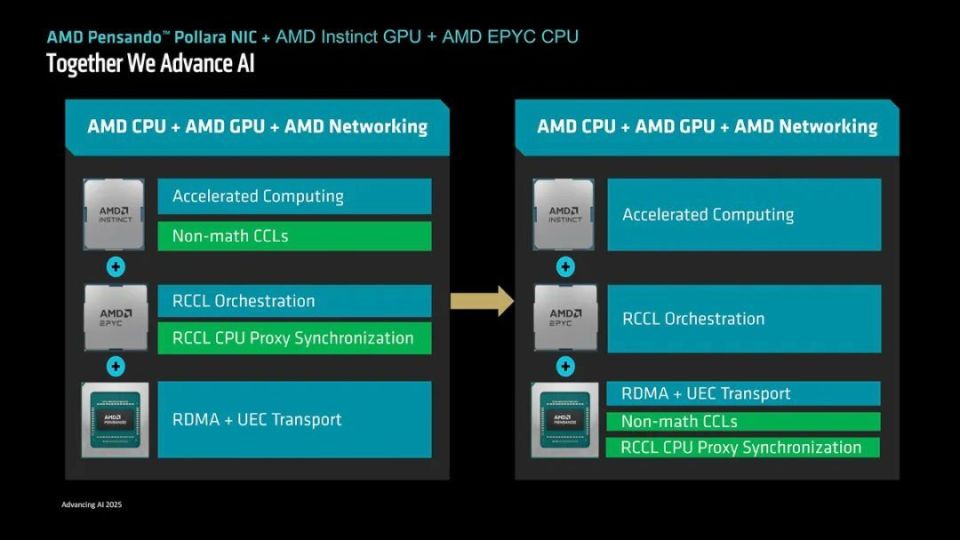
AMD可以提供灵活的CPU+GPU+NIC解决方案组合

在推出Pensando Pollara 400 AI NIC网卡之后,结合ROCm 7平台、EPYC处理器以及Instinct系列GPU,AMD已经可以从硬件到软件提供全方位且配置灵活的整体式解决方案,他们也借此成为了从软件到硬件都有完整方案的AI计算设备厂商,在构建开放、灵活、可扩展且高性价比AI基础设施的道路上迈出了重要的一步。
